主题
题目2: 大模型的量化与推理性能评测 40%
针对 DeepSeek-R1-Distill-Qwen-7B 模型开展模型量化实验 ;
- 实验需采用
INT8、INT4、GPTQ、AWQ等常见量化方法,在保证模型困惑度(Perplexity,PPL)不显著劣化的前提下,旨在降低显存占用 ; - 数据集:统一采用
WikiText-103-v1的test文件作为评测基准(示例来源),该测试集共包含 4,358 条文本 ; - 困惑度(PPL)计算的解释、原理及标准实现参考相关技术文档中示例: 使用Transformers 中的 GPT-2 计算困惑度 一节所展示的实现方法 ;
- 评测计算从
WikiText-103-v1测试集中随机抽取100条非空文本作为评测数据 ; - 用于评测 FP16 基线和所有量化模型的样本子集必须完全相同 ;
- 必须
固定随机种子以确保每次抽取的样本一致 ; - 最大序列长度
max_length设置512;
评判标准
- 正确性:量化方法实现正确,严格按照指定参考文档中的代码示例实现评测,并在选定的固定样本子集上完成困惑度计算 。;
- 性能指标:量化模型的
PPL相对FP16基线上升幅度 ≤ 15%情况下,显存峰值越少越优 ; - 分析与展示:需给出量化下的结果对比表(包含
PPL、显存峰值),并分析精度——性能平衡策略,结果需 可复现 且具备 可解释性 。
项目源代码拉取
bash
$ git clone https://static.ksuser.cn/dcu/q2.git目录结构
bash
.
── q2
├─ models (在执行download.py后才会生成)
│ ├─ deepseek-ai
│ │ └─ DeepSeek-R1-Distill-Qwen-7B
│ └─ quantification
│ └─ DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4
├─ datasets (在执行download.py后才会生成)
│ └─ wikitext-103-v1
│ └─ test-00000-of-00001.parquet
├─ settings.py 设置(模型名称、量化与测评相关参数等)
├─ tools.py 公共工具函数
├─ download.py 下载基准模型/数据集
├─ quantificative.py 模型量化
├─ question.py 模型测试
├─ compute.py 模型困惑度(PPL)计算
├─ requirements.txt 项目依赖(仅当您在非海光DCU环境部署时才可使用)
└─ README.md 部分部署的注意事项配置文件 settings.py 部分参数配置说明
SEED: 采样随机种子,原始与量化模型必须使用同一值,保证样本子集完全一致PPL_SAMPLES: PPL 评测使用的样本条数(100)PPL_MAX_LENGTH与PPL_STRIDE: 滑动窗口评测的窗口与步幅(512)NUM_CALIBRATION_SAMPLES: 量化校准样本数,越大越稳定但显存占用更高MAX_SEQUENCE_LENGTH: 量化校准时的最大序列长度(512)
实际部署
注意
如您在 海光DCU 环境上,您需要进行专用的环境检测与依赖安装脚本(详见请至:第二题环境配置)
bash
$ curl -fsSL https://static.ksuser.cn/dcu/env-q2.sh | bash -s --接下来的所有步骤都需要在脚本创建的 dcu-q2 虚拟环境中进行!
1. 下载基准模型与数据集
您可借助 download.py 一键下载模型 DeepSeek-R1-Distill-Qwen-7B 与数据集 wikitext-103-v1/test-00000-of-00001.parquet,也可自行下载并存放与项目相关目录
bash
$ python download.pybash
(dcu-q2) root@worker-0:/public/home/xdzs2025_sspu_jy/work/q2# python download.py
Downloading Model from https://www.modelscope.cn to directory: /public/home/xdzs2025_sspu_jy/work/q2/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B
2025-10-20 01:57:04,504 - modelscope - INFO - Got 11 files, start to download ...
Downloading [configuration.json]: 100%|█████████████████████████████████████████████████████████████| 73.0/73.0 [00:01<00:00, 62.3B/s]
Downloading [config.json]: 100%|███████████████████████████████████████████████████████████████████████| 680/680 [00:01<00:00, 578B/s]
Downloading [LICENSE]: 100%|███████████████████████████████████████████████████████████████████████| 1.04k/1.04k [00:01<00:00, 899B/s]
Downloading [generation_config.json]: 100%|████████████████████████████████████████████████████████████| 181/181 [00:01<00:00, 150B/s]
Downloading [model.safetensors.index.json]: 100%|████████████████████████████████████████████████| 27.4k/27.4k [00:01<00:00, 23.3kB/s]
Downloading [figures/benchmark.jpg]: 100%|██████████████████████████████████████████████████████████| 759k/759k [00:01<00:00, 633kB/s]
Downloading [tokenizer_config.json]: 100%|███████████████████████████████████████████████████████| 3.00k/3.00k [00:00<00:00, 7.11kB/s]
Downloading [README.md]: 100%|███████████████████████████████████████████████████████████████████| 15.6k/15.6k [00:00<00:00, 26.4kB/s]
Downloading [tokenizer.json]: 100%|██████████████████████████████████████████████████████████████| 6.71M/6.71M [00:01<00:00, 6.22MB/s]
Downloading [model-00001-of-000002.safetensors]: 100%|███████████████████████████████████████████| 8.02G/8.02G [04:57<00:00, 28.9MB/s]
Downloading [model-00002-of-000002.safetensors]: 100%|███████████████████████████████████████████| 6.17G/6.17G [05:36<00:00, 19.7MB/s]
Processing 11 items: 100%|█████████████████████████████████████████████████████████████████████████| 11.0/11.0 [05:36<00:00, 30.6s/it]
2025-10-20 02:02:41,352 - modelscope - INFO - Download model 'deepseek-ai/DeepSeek-R1-Distill-Qwen-7B' successfully.1<10:02, 14.3MB/s]
模型已下载至/public/home/xdzs2025_sspu_jy/work/q2/models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | 19.0M/8.02G [00:01<07:05, 20.2MB/s]
/opt/conda/envs/dcu/lib/python3.10/site-packages/huggingface_hub/file_download.py:982: UserWarning: `local_dir_use_symlinks` parameter is deprecated and will be ignored. The process to download files to a local folder has been updated and do not rely on symlinks anymore. You only need to pass a destination folder as`local_dir`.███████████████████████████████▋ | 5.54G/6.17G [04:57<00:36, 18.6MB/s]
For more details, check out https://huggingface.co/docs/huggingface_hub/main/en/guides/download#download-files-to-local-folder..5MB/s]
warnings.warn(
wikitext-103-v1/test-00000-of-00001.parq(…): 100%|██████████████████████████████████████████████████| 722k/722k [00:01<00:00, 381kB/s]
数据集已下载至/public/home/xdzs2025_sspu_jy/work/q2/datasets/wikitext-103-v1/test-00000-of-00001.parquet运行完毕后您将会在项目根目录中看见 /models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B 模型目录与 /datasets/wikitext-103-v1/test-00000-of-00001.parquet 数据集目录
下载数据集默认从
huggingface.co下载如您无法访问huggingface则会自动切换为镜像站
hf-mirror.com
2. 测试基准模型是否可正常推理
bash
$ python question.py --model rawbash
(dcu-q2) root@worker-0:/public/home/xdzs2025_sspu_jy/work/q2# python question.py
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████| 2/2 [00:26<00:00, 13.07s/it]
/opt/conda/envs/dcu/lib/python3.10/site-packages/torch/nn/modules/module.py:1326: UserWarning: expandable_segments not supported on this platform (Triggered internally at /home/pytorch/c10/hip/HIPAllocatorConfig.h:30.)
return t.to(
============== 内容测试 ==============
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py:301: UserWarning: Attempting to use hipBLASLt on an unsupported architecture! Overriding blas backend to hipblas (Triggered internally at /home/pytorch/aten/src/ATen/Context.cpp:296.)
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: Flash attention was not supported for current architecture, attempting to run on torch native impl for backend=math (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:216.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: 1Torch was not compiled with memory efficient attention. (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:663.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
你好,我是小明,我遇到了一个数学题,题目是这样的:小明有一个正方形的花园,边长是5米,他想在花园的周围种一圈树,每隔1米种一棵,那么他一共需要种多少棵树?小明现在有点困惑,不知道怎么计算,所以我想请教你来帮忙解答这个问题。
好,我现在要解决这个问题,首先我需要理解题目的意思。题目说小明有一个正方形的花园,边长是5米
==========================================提示
您也可使用下列命令自定义 prompt
bash
$ python question.py --model raw --prompt "你好,我的任务是"3. 量化基准模型
此步骤使用 llmcompressor 将模型进行 AWQ 量化,过程较为漫长,请耐心等候
bash
$ python quantificative.pybash
(dcu-q2) root@worker-0:/public/home/xdzs2025_sspu_jy/work/q2# python quantificative.py
`torch_dtype` is deprecated! Use `dtype` instead!
/opt/conda/envs/dcu/lib/python3.10/site-packages/accelerate/utils/modeling.py:821: UserWarning: expandable_segments not supported on this platform (Triggered internally at /home/pytorch/c10/hip/HIPAllocatorConfig.h:30.)
_ = torch.tensor([0], device=i)
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████| 2/2 [00:28<00:00, 14.11s/it]
2025-10-19T22:47:21.079956+0800 | reset | INFO - Compression lifecycle reset
2025-10-19T22:47:21.091611+0800 | _create_default_logger | INFO - Logging all LLM Compressor modifier-level logs to sparse_logs/19-10-2025_22.47.21.log
2025-10-19T22:47:21.093649+0800 | from_modifiers | INFO - Creating recipe from modifiers
2025-10-19T22:47:21.250933+0800 | on_initialize | INFO - No AWQModifier.mappings provided, inferring from model...
Resolving mapping 1/4 (0 skipped): : 28it [00:00, 1294.38it/s]
Resolving mapping 2/4 (27 skipped): : 28it [00:00, 3659.95it/s]
Resolving mapping 3/4 (0 skipped): : 28it [00:00, 2163.41it/s]
Resolving mapping 4/4 (0 skipped): : 28it [00:00, 3921.87it/s]
2025-10-19T22:47:21.304043+0800 | initialize | INFO - Compression lifecycle initialized for 1 modifiers
2025-10-19T22:47:21.304607+0800 | IndependentPipeline | INFO - Inferred `SequentialPipeline` for `AWQModifier`
Preparing cache: 100%|███████████████████████████████████████████████████████████████████████████| 2000/2000 [00:03<00:00, 649.13it/s]
(1/29): Calibrating: 0%| | 0/2000 [00:00<?, ?it/s]/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py:301: UserWarning: Attempting to use hipBLASLt on an unsupported architecture! Overriding blas backend to hipblas (Triggered internally at /home/pytorch/aten/src/ATen/Context.cpp:296.)
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: Flash attention was not supported for current architecture, attempting to run on torch native impl for backend=math (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:216.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: 1Torch was not compiled with memory efficient attention. (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:663.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
(1/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:25<00:00, 79.46it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.01s/it]
(1/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:15<00:00, 133.20it/s]
(2/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 88.31it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.15s/it]
(2/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 150.81it/s]
(3/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 84.66it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.05s/it]
(3/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 150.90it/s]
(4/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 86.43it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:11<00:00, 103.98s/it]
(4/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.08it/s]
(5/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 84.38it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.02s/it]
(5/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.20it/s]
(6/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 85.85it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.03s/it]
(6/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.19it/s]
(7/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 83.66it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:11<00:00, 103.97s/it]
(7/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.46it/s]
(8/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 85.15it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.05s/it]
(8/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 150.43it/s]
(9/29): Calibrating: 100%|████████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 84.06it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.07s/it]
(9/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 150.23it/s]
(10/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 85.18it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.11s/it]
(10/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.37it/s]
(11/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 85.83it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.14s/it]
(11/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.37it/s]
(12/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 87.65it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.06s/it]
(12/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.63it/s]
(13/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 87.25it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.02s/it]
(13/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.81it/s]
(14/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 86.72it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.04s/it]
(14/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.51it/s]
(15/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 87.04it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:11<00:00, 103.98s/it]
(15/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.55it/s]
(16/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 86.14it/s]
Smoothing: 33%|█████████████████████████████▎ | 1/3 [01:13<02:26, 73.02s/it]Smoothing: 67%|██████████████████████████████████████████████████████████ | 2/3 [04:08<02:13, 133.11s/it]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:11<00:00, 103.99s/it]
(16/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.55it/s]
(17/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 84.35it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.05s/it]
(17/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.21it/s]
(18/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 85.43it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.05s/it]
(18/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.36it/s]
(19/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 86.27it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:11<00:00, 103.95s/it]
(19/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.90it/s]
(20/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 85.33it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:11<00:00, 103.94s/it]
(20/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.57it/s]
(21/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 86.33it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:11<00:00, 103.97s/it]
(21/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.69it/s]
(22/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 87.24it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.13s/it]
(22/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.10it/s]
(23/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 86.54it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.16s/it]
(23/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.15it/s]
(24/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:23<00:00, 86.82it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.23s/it]
(24/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.28it/s]
(25/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 87.81it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.13s/it]
(25/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.24it/s]
(26/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 88.30it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.14s/it]
(26/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.78it/s]
(27/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 90.71it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.04s/it]
(27/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 151.62it/s]
(28/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:20<00:00, 96.81it/s]
Smoothing: 100%|███████████████████████████████████████████████████████████████████████████████████████| 3/3 [05:12<00:00, 104.08s/it]
(28/29): Propagating: 100%|██████████████████████████████████████████████████████████████████████| 2000/2000 [00:13<00:00, 152.19it/s]
(29/29): Calibrating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:22<00:00, 90.82it/s]
Smoothing: 0it [00:00, ?it/s]
(29/29): Propagating: 100%|███████████████████████████████████████████████████████████████████████| 2000/2000 [00:21<00:00, 91.49it/s]
Smoothing: 0it [00:00, ?it/s]
Calibrating weights: 196it [00:07, 27.20it/s]
2025-10-20T01:31:30.685563+0800 | finalize | INFO - Compression lifecycle finalized for 1 modifiers
2025-10-20T01:31:30.777800+0800 | post_process | WARNING - Optimized model is not saved. To save, please provide`output_dir` as input arg.Ex. `oneshot(..., output_dir=...)`
2025-10-20T01:31:30.824596+0800 | get_model_compressor | INFO - skip_sparsity_compression_stats set to True. Skipping sparsity compression statistic calculations. No sparsity compressor will be applied.
Compressing model: 196it [00:11, 17.55it/s]
量化模型已保存至./models/quantification/DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4*如您遇到下列输出内容,则代表您的 GPU显存 可能不足
bash
torch.OutOfMemoryError: HIP out of memory.
Tried to allocate 24.00 MiB.
GPU 0 has a total capacity of 15.98 GiB of which 0 bytes is free.
Of the allocated memory 15.71 GiB is allocated by PyTorch, and 59.98 MiB is reserved by PyTorch but unallocated.
If reserved but unallocated memory is large try setting PYTORCH_HIP_ALLOC_CONF=expandable_segments:True to avoid fragmentation.
See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)此时您可编辑 settings.py 中的 NUM_CALIBRATION_SAMPLES,降低该数值以减小量化的校准样本数,从而减小显存占用
python
# quantification
QUANTIFICATIVE_MODEL_ID = "quantification/DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4"
QUANTIFICATIVE_MODEL_DIR = "./models/" + QUANTIFICATIVE_MODEL_ID
NUM_CALIBRATION_SAMPLES = 2000 # 降低校准样本数
MAX_SEQUENCE_LENGTH = 512 # 避免不必要的长序列校准
SEED = 20251113620同时设置环境变量 export PYTORCH_HIP_ALLOC_CONF=expandable_segments:True 来启动可扩展内存段,减少内存碎片
4. 测试量化后的模型是否可正常推理
bash
$ python question.py --model quantized提示
您也可使用下列命令自定义 prompt
bash
$ python question.py --model quantized --prompt "你好,我的任务是"5. 分别计算量化前后模型的困惑度(PPL),并同时获取显存峰值
- 在命令行中输入如下命令测评基准
DeepSeek-R1-Distill-Qwen-7B模型的困惑度
bash
$ python compute.py --model rawbash
(dcu-q2) root@worker-0:/public/home/xdzs2025_sspu_jy/work/q2# python compute.py
/opt/conda/envs/dcu/lib/python3.10/site-packages/accelerate/utils/modeling.py:821: UserWarning: expandable_segments not supported on this platform (Triggered internally at /home/pytorch/c10/hip/HIPAllocatorConfig.h:30.)
_ = torch.tensor([0], device=i)
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████| 2/2 [00:26<00:00, 13.47s/it]
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py:301: UserWarning: Attempting to use hipBLASLt on an unsupported architecture! Overriding blas backend to hipblas (Triggered internally at /home/pytorch/aten/src/ATen/Context.cpp:296.)
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: Flash attention was not supported for current architecture, attempting to run on torch native impl for backend=math (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:216.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: 1Torch was not compiled with memory efficient attention. (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:663.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
{
"ppl": 236.52647399902344,
"samples": 100,
"max_length": 512,
"stride": 512,
"dtype": "float16",
"multi_gpu": true,
"device": "cuda",
"memory": {
"backend": "cuda/rocm",
"per_device": [
{
"index": 0,
"torch_peak_alloc_mb": 2931.85,
"reserved_alloc_mb": 3044.0
},
{
"index": 1,
"torch_peak_alloc_mb": 4111.82,
"reserved_alloc_mb": 3044.0
},
{
"index": 2,
"torch_peak_alloc_mb": 4111.82,
"reserved_alloc_mb": 3044.0
},
{
"index": 3,
"torch_peak_alloc_mb": 4378.12,
"reserved_alloc_mb": 3044.0
}
]
},
"dataset_path": "./datasets/wikitext-103-v1/test-00000-of-00001.parquet",
"model_dir": "./models/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
}- 在命令行中输入如下命令测评量化
DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4模型的困惑度
bash
$ python compute.py --model quantizedbash
(dcu-q2) root@worker-0:/public/home/xdzs2025_sspu_jy/work/q2# python compute.py --model quantized
Compressing model: 196it [00:00, 491.18it/s]
/opt/conda/envs/dcu/lib/python3.10/site-packages/accelerate/utils/modeling.py:821: UserWarning: expandable_segments not supported on this platform (Triggered internally at /home/pytorch/c10/hip/HIPAllocatorConfig.h:30.)
_ = torch.tensor([0], device=i)
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████████████| 2/2 [00:12<00:00, 6.33s/it]
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/models/qwen2/modeling_qwen2.py:301: UserWarning: Attempting to use hipBLASLt on an unsupported architecture! Overriding blas backend to hipblas (Triggered internally at /home/pytorch/aten/src/ATen/Context.cpp:296.)
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: Flash attention was not supported for current architecture, attempting to run on torch native impl for backend=math (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:216.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
/opt/conda/envs/dcu/lib/python3.10/site-packages/transformers/integrations/sdpa_attention.py:83: UserWarning: 1Torch was not compiled with memory efficient attention. (Triggered internally at /home/pytorch/aten/src/ATen/native/transformers/hip/sdp_utils.cpp:663.)
attn_output = torch.nn.functional.scaled_dot_product_attention(
{
"ppl": 247.9794158935547,
"samples": 100,
"max_length": 512,
"stride": 512,
"dtype": "float16",
"multi_gpu": true,
"device": "cuda",
"memory": {
"backend": "cuda/rocm",
"per_device": [
{
"index": 0,
"torch_peak_alloc_mb": 0.0,
"reserved_alloc_mb": 0.0
},
{
"index": 1,
"torch_peak_alloc_mb": 3399.68,
"reserved_alloc_mb": 0.0
},
{
"index": 2,
"torch_peak_alloc_mb": 7417.84,
"reserved_alloc_mb": 0.0
},
{
"index": 3,
"torch_peak_alloc_mb": 9020.43,
"reserved_alloc_mb": 0.0
}
]
},
"dataset_path": "./datasets/wikitext-103-v1/test-00000-of-00001.parquet",
"model_dir": "./models/quantification/DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4"
}- 将两者困惑度进行比对
基准模型PPL -> 236.52647399902344
量化模型PPL -> 247.9794158935547利用
rocm-smi命令获取实时显存占用基准模型:
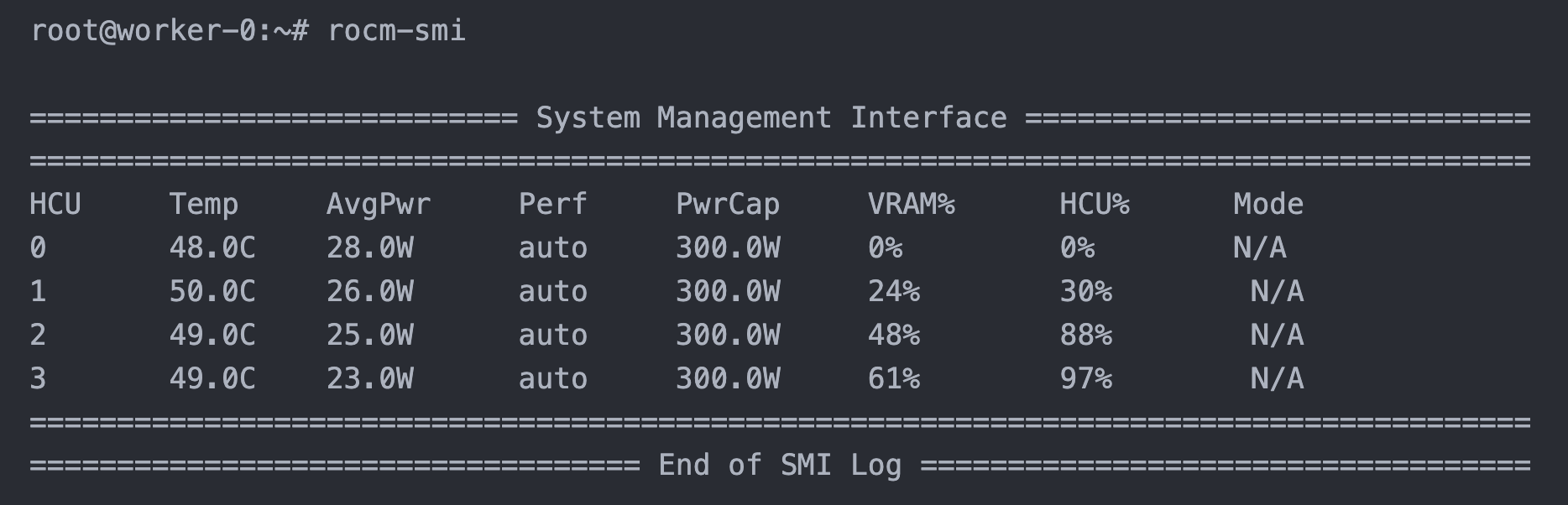
量化模型:
推理比对要点:
- 随机抽样:从
WikiText-103-v1的test-00000-of-00001.parquet中抽取100条非空文本。使用固定随机种子SEED,保证“原始 vs 量化”样本子集一致。 - 滑动窗口:
max_length=512与stride=512,按参考示例进行分段,逐段计算 loss 并在所有段上取均值;最终PPL = exp(mean_loss)。 - 设备与精度:自动选择设备(DCU/CUDA、MPS 或 CPU)与 dtype(半精度/全精度),并在评测前重置显存峰值统计。
- 随机抽样:从
量化原理解释
本项目使用 AWQ (W4A16) 对称量化,旨在使PPL上升幅度最小的情况下尽可能减小显存占用
- AWQ(Activation-aware Weight Quantization):在校准数据上估计激活分布,寻找对感知损失最小的权重量化缩放,从而在较低比特宽度下保持高保真度。对称 W4A16 指权重 4bit、激活 16bit,避免零点压缩带来的兼容性问题。
- 校准数据:使用
WikiText-103-v1 test,通过前向传播收集统计量,优化每层线性模块的比例因子。 - 目标层:本项目仅量化
Linear层,并忽略lm_head以减少输出层误差的放大。
可扩展的量化思路(本项目未实现,供延展对比使用):
- INT8/INT4(如 bitsandbytes 的量化加载)
- GPTQ(梯度近似的逐层权重量化)
困惑度(PPL)计算原理解释
PPL 是衡量语言模型对样本的“困惑”程度,本质上是按 token 的平均负对数似然的指数映射。
- 在项目中,我们采用滑动窗口处理长文本。对每一段窗口,模型返回交叉熵损失(与“预测下一个 token”的 NLL 等价)。
- 将所有窗口段的 loss 求均值后,再取自然指数得到 PPL:
PPL 计算关键因素:
- 样本子集固定(抽样前设置相同随机种子);
- 最大序列长度与步幅固定为;
- 关闭
use_cache以减少缓存带来的显存影响(。
精度——性能平衡策略
在“PPL 升幅 ≤ 15%”的前提下,优先选择显存峰值更低的方案。实践策略:
- 校准规模
NUM_CALIBRATION_SAMPLES越大,量化稳定性通常更好,但量化过程占用的显存与时长也会随之增大,样本数不得少于数据集中非空数据数; - 量化位宽
W4A16,若进一步降显存,可探索更激进的配置,但需重新评估 PPL 升幅是否仍 ≤ 15%
项目比对结果:
| 模型 | 方法 | dtype | PPL | 相对升幅 | 显存峰值(GB) | 相对降幅 |
|---|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-7B | FP16 基线 | fp16 | 236.53 | - | 21.28 | - |
| DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4 | AWQ W4A16 | int4-w4a16 | 247.978 | +4.84% | 16 | -24.81% |
量化模型下载
您可下载已经通过该项目量化过的模型来进行结果复现与比对
- HuggingFace:https://huggingface.co/KsuserKqy/DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4/
- ModelScope:http://modelscope.cn/models/ksuserKqy/DeepSeek-R1-Distill-Qwen-7B-AWQ-INT4/
常见问题与排障
- DCU/ROCm 报错 “HIP out of memory”:参考上文的显存缓解组合,优先设置
PYTORCH_HIP_ALLOC_CONF=expandable_segments:True,并降低NUM_CALIBRATION_SAMPLES - PPL 不一致:检查是否改动了
SEED、PPL_SAMPLES、PPL_MAX_LENGTH、PPL_STRIDE或数据文件路径;确保原始与量化两次评测相关参数一致。
许可与引用
- 本项目遵行 Apache License 2.0协议
- 模型与数据遵循其各自的开源协议与使用条款。
- 该项目引用与参考了下列开源项目(包括但不限于):